2채널 Crosstalk cancellation (CTC)은 기본적으로 스피커에 적용되는 시스템이다.
스피커로 헤드폰의 공간감을 느끼게 해줄 수 있는 기술이다.
기술의 배경 먼저 설명하겠다.
헤드셋의 경우에는 좌, 우 채널이 귀에 밀착되어 양 귀에 간섭없이 재생될 수 있어 제어가 용이하다. Head related transfer function(HRTF, 머리전달함수)를 헤드폰에 재생하는 음원에 Convolution 해주면 (이는 Adobe audition, matlab 등에서 가능) HRTF의 특성에 따라 소리가 마치 움직이면서 들리는 듯한 동적인 느낌을 줄 수 있다.
반면 스피커의 경우에는 좌, 우 채널이 좌이, 우이 각각 영향을 주는 것이 아니라 동시에 양귀에 영향을 주므로 이는 제어에 어려움을 준다. 사실 공간감을 주기에는 재생의 공간폭이 좁은 헤드셋에 비해서 스피커가 훨씬 리얼하지만 어려움이 있는 것이다. 따라서 스피커에서는 동적인 느낌을 소리에 주기 위해서 dolby 와 같은 기술이 개발되어 있고 그 중 하나가 CTC 이다.
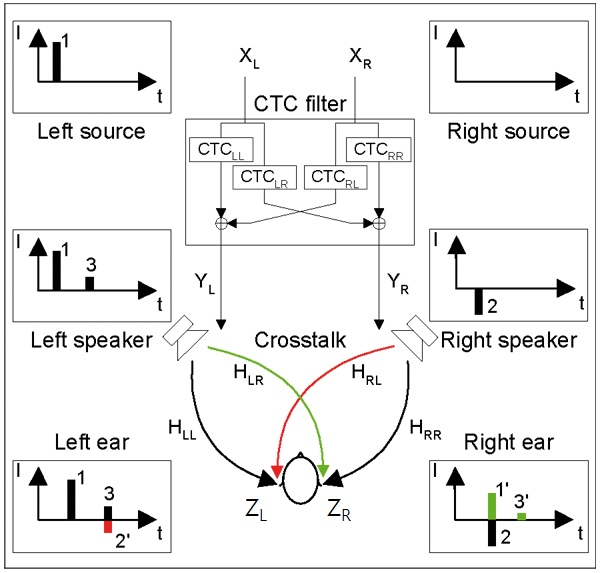
CTC는 좌측에서 나온 신호를 좌측 귀에만 전달이 되도록 우측으로 전달되는 신호를 제거하고 반대로 우측에서 나온 신호를 우측 귀에만 전달하도록 좌측으로 전달되는 신호를 제거하는 기술이다. 그 개요는 아래의 그림과 같다.
다시 말하면 좌채널에서 오른쪽귀로 가는 신호에 대한 경로와 우채널에서 왼쪽귀로 가는 신호를 지워서 좌채널의 신호가 왼쪽귀로만 가고 우채널의 신호가 오른쪽 귀로만 가게 하는 것인데, 이를 위해서는 전달경로에 대한 데이터 확보가 필요하다.
이는 머리전달함수와 동일한 전달경로에 대한 정보로 생각할 수 있는데, 머리전달함수에 대해서는 추후 설명하도록 하고, 간단하게 데이터 확보 방법만 구두로 설명하겠다.
무향실에서 레코딩 된 impulse response (IRs, 충격응답)를 기본 h(x) 전달함수로 생각하여 좌채널과 우채널에서 각각 재생을 한다. 이 때에 CTC를 이용하여 듣는 청자의 위치는 고정되어 있어야 한다. CTC는 정해진 위치에서 조금만 벗어나도 정위감이 크게 흔들리므로 레코딩 단계에서부터 스피커와 청자의 위치를 고정해야한다.
고정된 청자의 위치에서 dummy head 2채널 마이크로폰을 이용하여 좌이와 우이에 대해서 좌채널과 우채널에서 재생된 IRs를 녹음하여 데이터로 확보하면 된다. (IRs_LL, IRs_LR, IRs_RR, IRs_RL 4개의 파일이 2번의 재생에 대해서 양쪽귀 데이터 생성된다.) 그림에서는 IRs 대신 H로 명시되어 있다.
자 이제 사후처리 과정을 통해 CTC 음원 생성만이 남았다. 수식으로는 다음과 같다.
-
Z_L = Y_L*H_LL+Y_R*H_RL
-
Z_R= Y_R*H_RR+Y_L*H_LR
- Z는 여기서 최종 생성되는 CTC가 적용된 left, right 채널 음원이다. (즉 output 값)
- Y는 crosstalk을 적용하고자 하는 음원의 left, right 채널 음원이다. (즉 Input 값)
- H는 앞서 설명하였듯이 사전에 레코딩을 통해 확보된 전달함수 데이터이다. (총 4개, 어찌보면 상수로 볼 수 있다.)
- *은 여기서 곱셈이 아니고 convolution이다. (합성곱)
여기서 주의사항은 두 개의 식을 통해서 Y_L, Y_R을 식으로 도출했을 때에 분모가 0이 되지 않으려면 H_LL*H_RR - H_LR*H_RL이 0이면 안된다. 이게 0이 될 때에 문제가 발생하는 것이다. 0 이 된다는 뜻은 좌채널 재생시 양쪽귀로 들어오는 신호가 차이가 없이 완전히 같다는 뜻이다. (반대로 우채널 재생시 양쪽귀로 들어오는 신호가 동일하다는 것도 됨). 또한 강조하지만 앞서 말했듯이 이는 고정된 스피커, 청자 위치에 대해서 전달함수를 먼저 확보한 상황에서 사후처리된 음원을 통해 구성되기 떄문에 반드시 정해진 상황에서만 적용이 가능하다. (청자 위치에는 높이도 포함되니 앉거나 섰을때도 다르다.)
이러한 한계점으로 인해 근래에는 dynamic CTC를 연구하는 것도 하나의 주제이다. Kinect, 자이로 같은 위치와 머리 돌림각 센서를 연동하여 위치와 머리의 각도가 변할때마다 전달함수 데이터를 재설정하여 CTC 음원을 실시간 생성하는 것을 목표로 한다. (실상으로 무지 어렵다..)
개인적으로는 CTC가 입체감이나 동적인 느낌을 정말 잘 나타내지만 이러한 한계점으로 인해 얼마나 상용화될 수 있는 기술인지는 모르겠다.
그리고 신호처리 분야는 이론적으로 이해했더라도 이게 도대체 어떻게 이렇게 가능하지..? 라는 것은 필자도 잘 감이 안 온다. ㅎㅎ 너무 어려움
'음환경, 소음진동' 카테고리의 다른 글
| 음원 위치추적의 기초 (Directinon Of Arrival, DOA) (8) | 2021.07.26 |
|---|---|
| 머리전달함수(Head Related Transfer Function, HRTF)에 대하여 (0) | 2021.07.26 |
| 실내공간 음향의 기본이 되는 잔향시간(Reverberation time, RT)의 이해 (0) | 2021.03.03 |
| 양이상관함수 (Interaural cross-correlation function, IACF)의 이해 (0) | 2021.02.24 |
| 자기상관함수 (Auto correlation function, ACF)의 음향에 대한 이용 (0) | 2021.02.24 |